
Kafka概述
什么是Kafka?
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
- Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
- Kafka最初是由LinkedIn公司开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
- Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
- 无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
Kafka架构以及相关概念
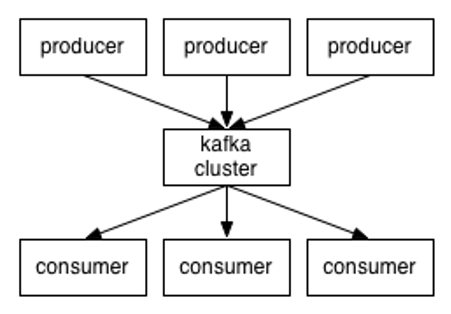

- Producer :消息生产者,就是向kafka broker发消息的客户端;
- Consumer :消息消费者,向kafka broker取消息的客户端;
- Topic :可以理解为一个队列;
- Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
- Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
- Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
Kafka生产过程分析
写入方式
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
分区(Partition)
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成。
分区的原则
(1)指定了patition,则直接使用;
(2)未指定patition但指定key,通过对key的value进行hash出一个patition;
(3)patition和key都未指定,使用轮询选出一个patition。
DefaultPartitioner类:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
副本(Replication)
同一个partition可能会有多个replication(对应 server.properties 配置中的 default.replication.factor=N)。没有replication的情况下,一旦broker 宕机,其上所有 patition 的数据都不可被消费,同时producer也不能再将数据存于其上的patition。引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据。
Kafka写入流程
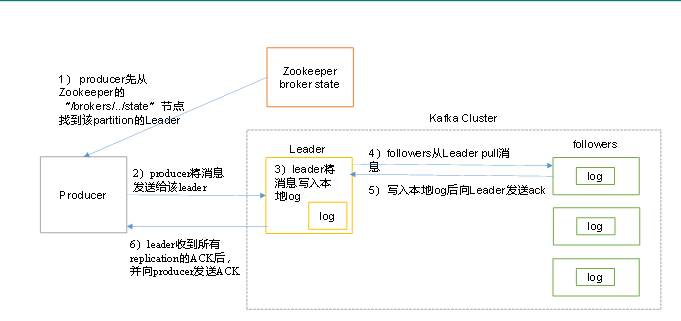
- producer先从zookeeper的 "/brokers/.../state"节点找到该partition的leader
- producer将消息发送给该leader
- leader将消息写入本地log
- followers从leader pull消息,写入本地log后向leader发送ACK
- leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit 的offset)并向producer发送ACK
Broker 保存消息
存储方式
物理上把topic分成一个或多个patition(对应 server.properties 中的num.partitions=3配置),每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件)。
存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
1)基于时间:log.retention.hours=168
2)基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
Zookeeper存储结构
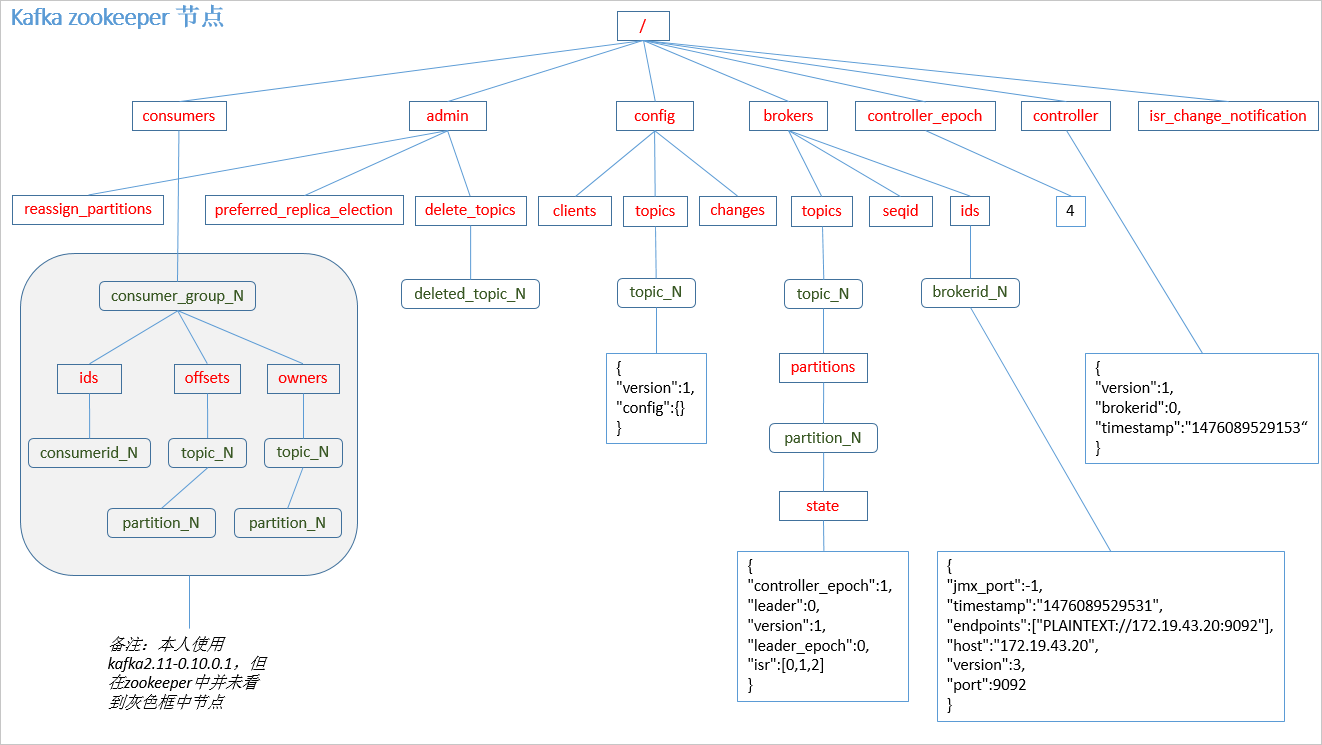
注意:producer不在zk中注册,消费者在zk中注册。
- 本文标签: Kafka
- 本文链接: http://www.lzhpo.com/article/10
- 版权声明: 本文由lzhpo原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐










相关文章
关于我


