
MapReduce概览以及实现词频统计
MapReduce
MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
Mapreduce,编程模型.
映射 + 化简。GFS NDFS
Map reduce
extends Mapper{
map(){
...
}
}
extends Reducer{
reduce(){
...
}
}
Shuffle
其中在Mapper和Reduce之间有一个Shuffle过程,也就是数据分发过程,意思就是在M和R之间进行数据分发。
Map端的工作,就是预先产生的kv进行分组。
数据倾斜
什么是数据倾斜?
数据倾斜在MapReduce编程模型中十分常见,用最通俗易懂的话来说,数据倾斜无非就是大量的相同key被partition分配到一个分区里,造成了'一个人累死,其他人闲死'的情况,这种情况是我们不能接受的,这也违背了并行计算的初衷,首先一个节点要承受着巨大的压力,而其他节点计算完毕后要一直等待这个忙碌的节点,也拖累了整体的计算时间,可以说效率是十分低下的。
简单理解,就是在哈希的过程大量的key被分发到了一个分区里,其它分区都没有被分发,而这个分区都是要运转不过来了,这样就造成了数据倾斜。
如何解决数据倾斜?
1.增加jvm内存,这适用于第一种情况(唯一值非常少,极少数值有非常多的记录值(唯一值少于几千)),这种情况下,往往只能通过硬件的手段来进行调优,增加jvm内存可以显著的提高运行效率。
2.增加reduce的个数,这适用于第二种情况(唯一值比较多,这个字段的某些值有远远多于其他值的记录数,但是它的占比也小于百分之一或千分之一),我们知道,这种情况下,最容易造成的结果就是大量相同key被partition到一个分区,从而一个reduce执行了大量的工作,而如果我们增加了reduce的个数,这种情况相对来说会减轻很多,毕竟计算的节点多了,就算工作量还是不均匀的,那也要小很多。
3.自定义分区,这需要用户自己继承partition类,指定分区策略,这种方式效果比较显著。
4.重新设计key,有一种方案是在map阶段时给key加上一个随机数,有了随机数的key就不会被大量的分配到同一节点(小几率),待到reduce后再把随机数去掉即可。
5.使用combinner合并,combinner是在map阶段,reduce之前的一个中间阶段,在这个阶段可以选择性的把大量的相同key数据先进行一个合并,可以看做是local reduce,然后再交给reduce来处理,这样做的好处很多,即减轻了map端向reduce端发送的数据量(减轻了网络带宽),也减轻了map端和reduce端中间的shuffle阶段的数据拉取数量(本地化磁盘IO速率),推荐使用这种方法。
编写MapReduce代码
环境准备:确保本地配置了hadoop环境。
工具准备:
工具下载地址:https://github.com/steveloughran/winutils
把hadoop集群里面的core-site.xml文件拷贝到本地的resources目录下当做配置文件。
Mapper:
package com.lzhpo.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* <p>Create By IntelliJ IDEA</p>
* <p>Since:JDK1.8</p>
* <p>Author:zhpo</p>
*
* WCMapper
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text keyOut = new Text();
IntWritable valueOut = new IntWritable();
String[] arr = value.toString().split(" ");
for(String s : arr){
keyOut.set(s);
valueOut.set(1);
context.write(keyOut,valueOut);
}
}
}
Reduce:
package com.lzhpo.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* <p>Create By IntelliJ IDEA</p>
* <p>Since:JDK1.8</p>
* <p>Author:zhpo</p>
*
* WCReducer
*/
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* reduce
*/
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0 ;
for(IntWritable iw : values){
count = count + iw.get() ;
}
context.write(key,new IntWritable(count));
}
}
Main:
package com.lzhpo.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* <p>Create By IntelliJ IDEA</p>
* <p>Since:JDK1.8</p>
* <p>Author:zhpo</p>
*/
public class WCApp {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置job的各种属性
//作业名称
job.setJobName("WCApp");
//搜索类
job.setJarByClass(WCApp.class);
//设置输入格式
job.setInputFormatClass(TextInputFormat.class);
//添加输入路径
FileInputFormat.addInputPath(job,new Path(args[0]));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//WCMapper
job.setMapperClass(WCMapper.class);
//WCReducer
job.setReducerClass(WCReducer.class);
//reduce个数
job.setNumReduceTasks(1);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
System.out.println("运行成功!");
}
}
运行程序之前,配置程序的参数:
注意file和file之间有空格:
file:///E:/Code/HDFS/MR/Intput/a.txt file:///E:/Code/HDFS/MR/Output
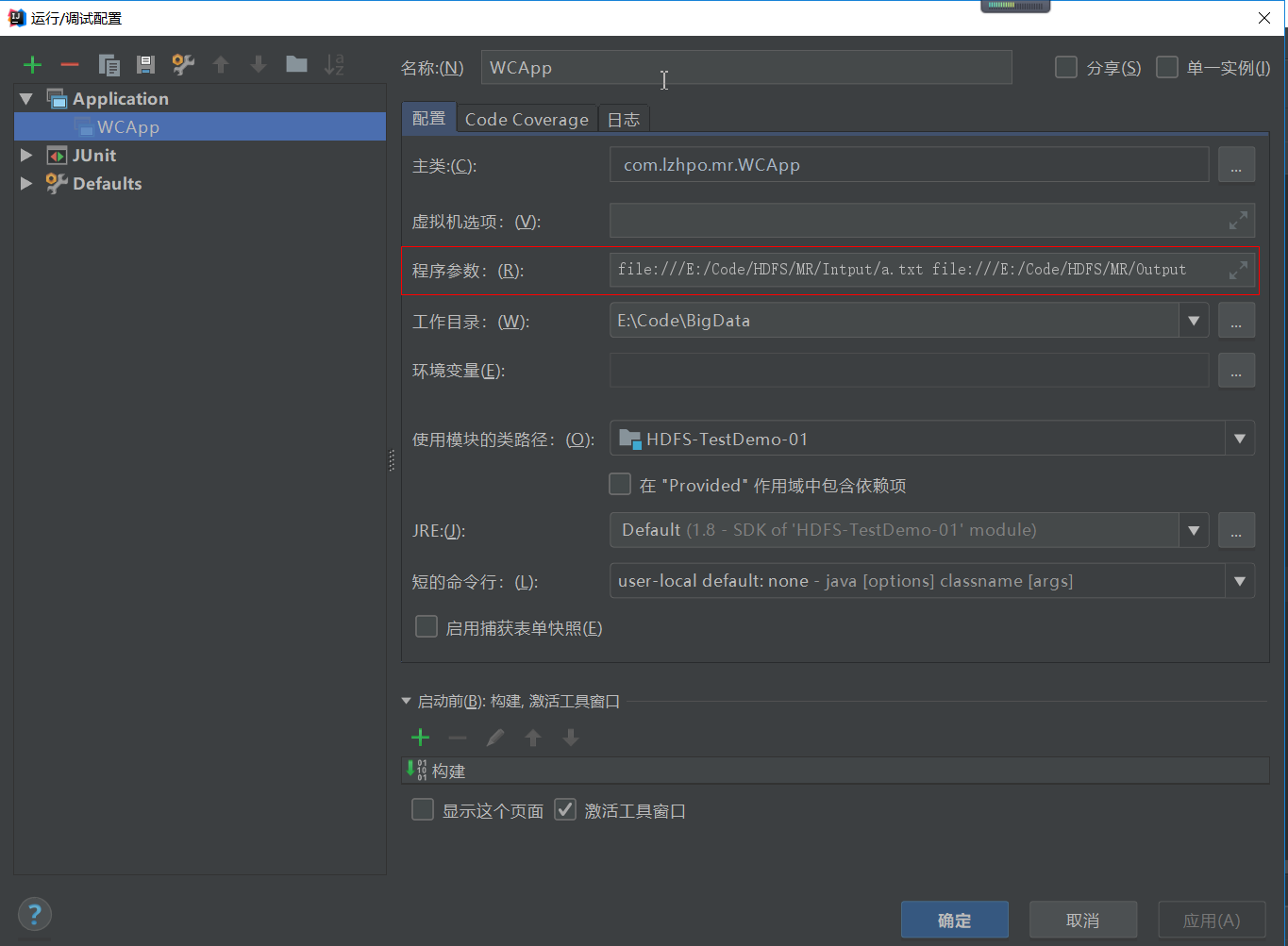
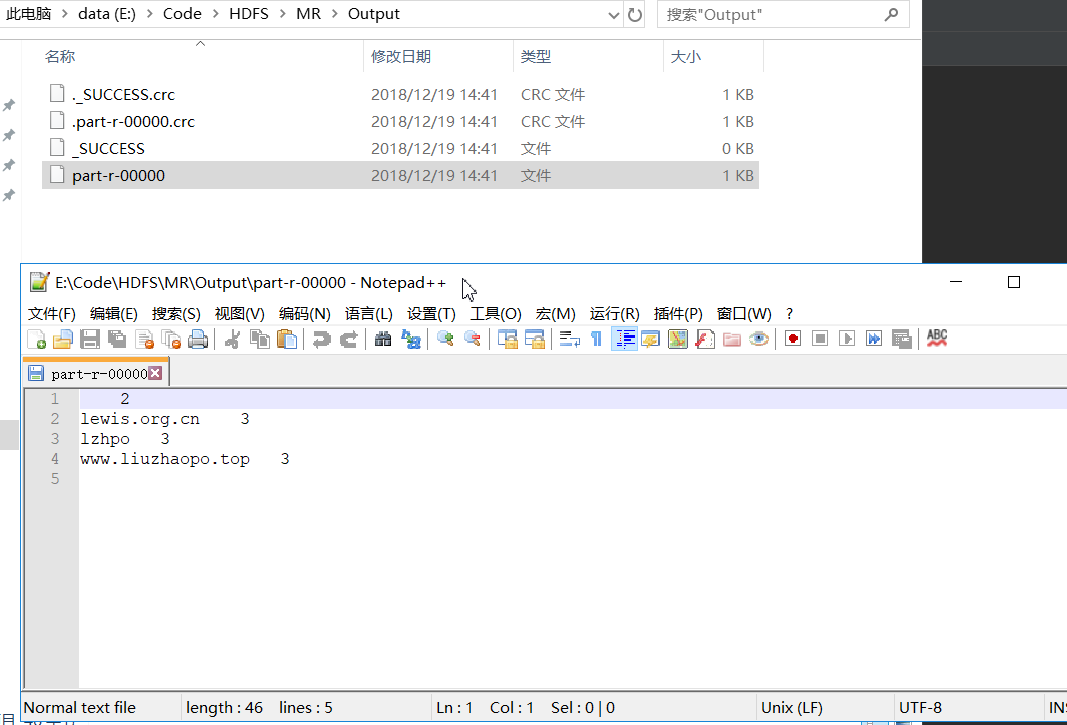
运行结果:
本地模式运行MapReduce流程
1.创建外部Job(mapreduce.Job),设置配置信息
2.通过jobsubmitter将job.xml + split等文件写入临时目录
3.通过jobSubmitter提交job给localJobRunner,
4.LocalJobRunner将外部Job 转换成成内部Job
5.内部Job线程,开放分线程执行job
6.job执行线程分别计算Map和reduce任务信息并通过线程池孵化新线程执行MR任务。
在hadoop集群上运行MapReduce
1. 将程序打成jar包:
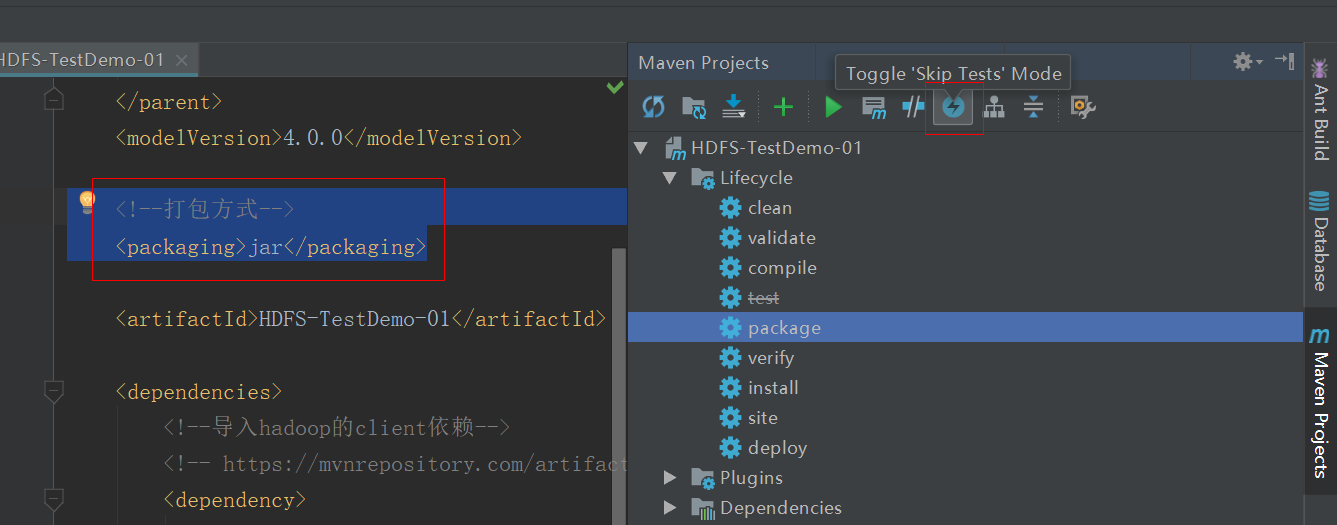
2.上传jar包
3.运行jar包
RunJar:hadoop jar。
jarFile:jar包名字。
[mainClass]:指明mian方法。
args...:运行参数,也就是输出输出目录。
hadoop jar HDFS-TestDemo-01-1.0-SNAPSHOT.jar com.lzhpo.mr.WCApp /user/joe/wordcount/input/file01 /user/joe/wordcount/output3

运行结果:
[root@hadoop1 WordCount-jar]# hadoop jar HDFS-TestDemo-01-1.0-SNAPSHOT.jar com.lzhpo.mr.WCApp /user/joe/wordcount/input/file01 /user/joe/wordcount/output3
18/12/19 15:23:56 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/12/19 15:23:56 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/12/19 15:23:58 INFO input.FileInputFormat: Total input files to process : 1
18/12/19 15:23:59 INFO mapreduce.JobSubmitter: number of splits:1
18/12/19 15:23:59 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/12/19 15:23:59 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545200929261_0001
18/12/19 15:24:00 INFO impl.YarnClientImpl: Submitted application application_1545200929261_0001
18/12/19 15:24:00 INFO mapreduce.Job: The url to track the job: http://hadoop1:8088/proxy/application_1545200929261_0001/
18/12/19 15:24:00 INFO mapreduce.Job: Running job: job_1545200929261_0001
18/12/19 15:24:12 INFO mapreduce.Job: Job job_1545200929261_0001 running in uber mode : false
18/12/19 15:24:12 INFO mapreduce.Job: map 0% reduce 0%
18/12/19 15:24:22 INFO mapreduce.Job: map 100% reduce 0%
18/12/19 15:24:29 INFO mapreduce.Job: map 100% reduce 100%
18/12/19 15:24:31 INFO mapreduce.Job: Job job_1545200929261_0001 completed successfully
18/12/19 15:24:31 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=52
FILE: Number of bytes written=396633
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=146
HDFS: Number of bytes written=22
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7154
Total time spent by all reduces in occupied slots (ms)=3906
Total time spent by all map tasks (ms)=7154
Total time spent by all reduce tasks (ms)=3906
Total vcore-milliseconds taken by all map tasks=7154
Total vcore-milliseconds taken by all reduce tasks=3906
Total megabyte-milliseconds taken by all map tasks=7325696
Total megabyte-milliseconds taken by all reduce tasks=3999744
Map-Reduce Framework
Map input records=1
Map output records=4
Map output bytes=38
Map output materialized bytes=52
Input split bytes=124
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=52
Reduce input records=4
Reduce output records=3
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=217
CPU time spent (ms)=2630
Physical memory (bytes) snapshot=388808704
Virtual memory (bytes) snapshot=4163776512
Total committed heap usage (bytes)=302120960
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=22
File Output Format Counters
Bytes Written=22
运行成功!
[root@hadoop1 WordCount-jar]# hdfs dfs -ls /user/joe/wordcount/output3
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-12-19 15:24 /user/joe/wordcount/output3/_SUCCESS
-rw-r--r-- 1 root supergroup 22 2018-12-19 15:24 /user/joe/wordcount/output3/part-r-00000
[root@hadoop1 WordCount-jar]# hdfs dfs -cat /user/joe/wordcount/output3/part-r-00000
Bye 1
Hello 1
World 2
[root@hadoop1 WordCount-jar]#
运行过程中再YARN上也可以查看的:
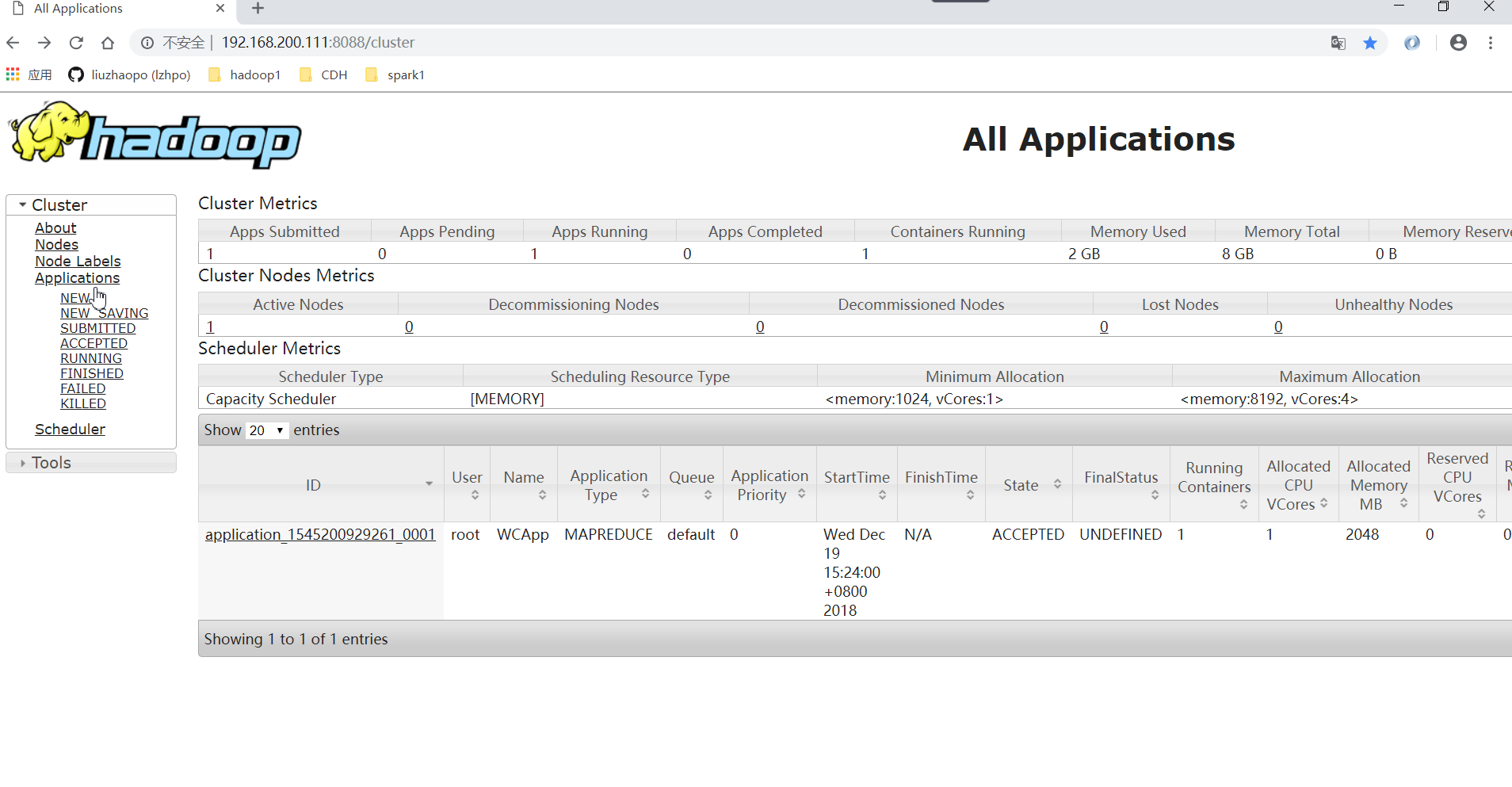
附加:
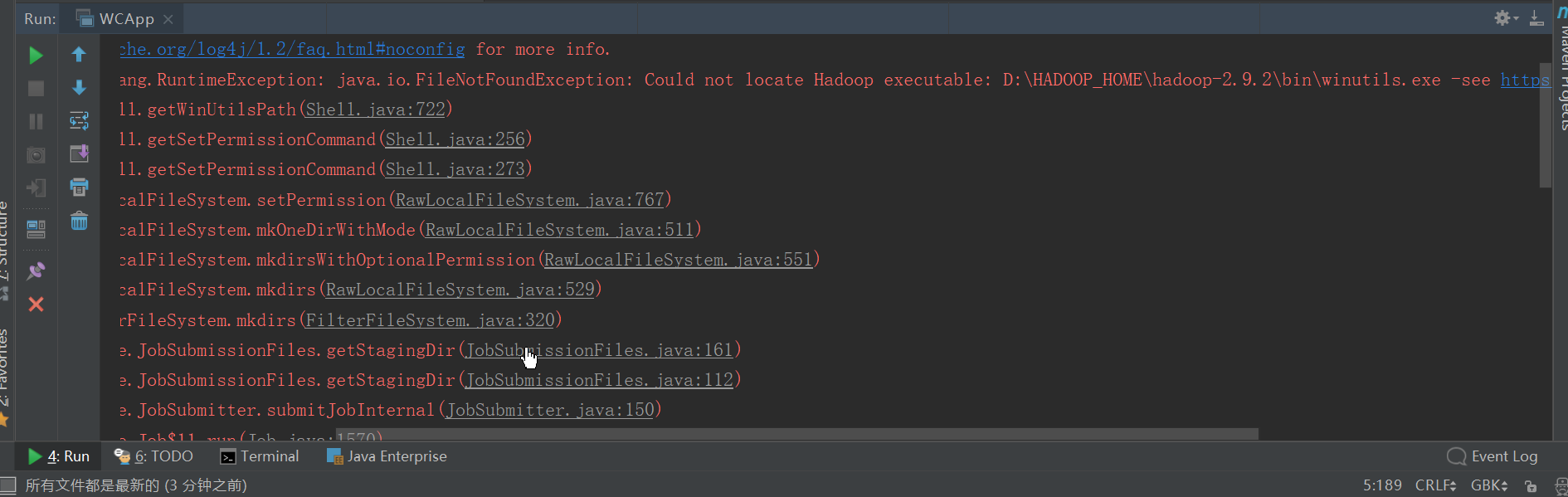
以下就是没有那两个工具,造成的异常。
没有winutils.exe:
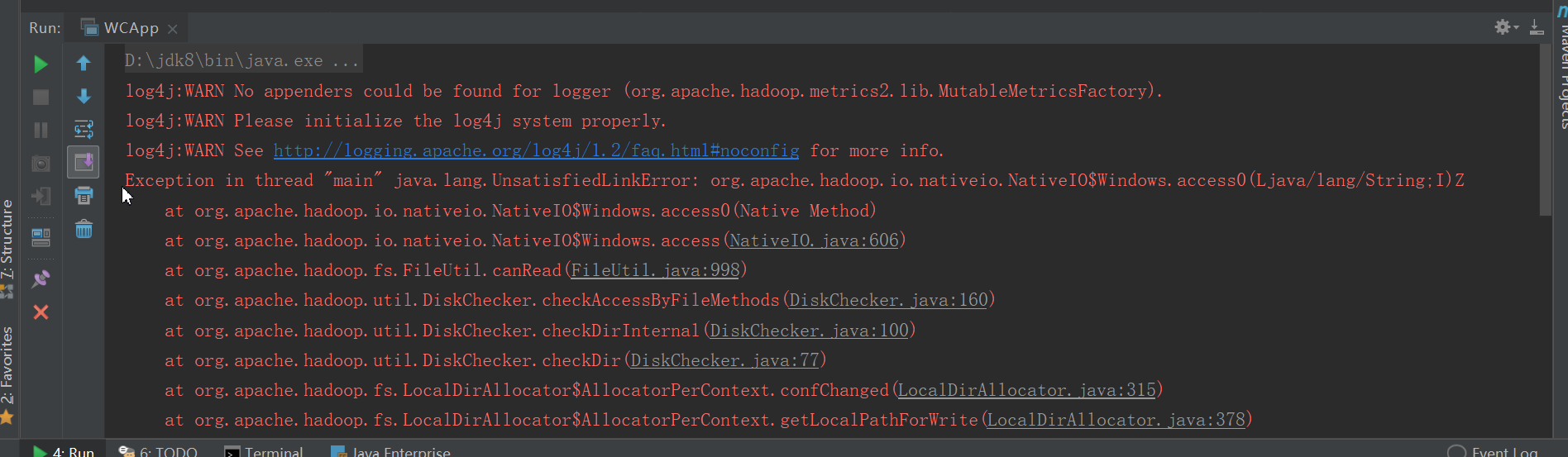
没有hadoop.dll:
- 本文标签: MapReduce Hadoop
- 本文链接: http://www.lzhpo.com/article/44
- 版权声明: 本文由lzhpo原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐










相关文章
关于我


