
原创
wordcount之Spark与Hadoop比较
温馨提示:
本文最后更新于 2018年07月13日,已超过 2,450 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
WordCount
1. hadoop版
首先,我们在/root/hadoop-test/文件夹下,vi一个wordcount.txt,内容如下:
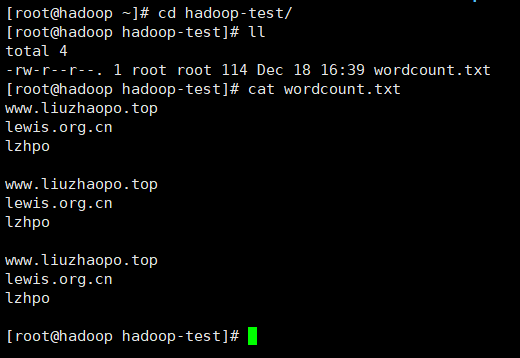
之后,在HDFS下创建一个/test文件夹,用于存放我们的wordcount文本文件,将/root/hadoop-test/wordcount.txt上传到HDFS的/test文件夹下:

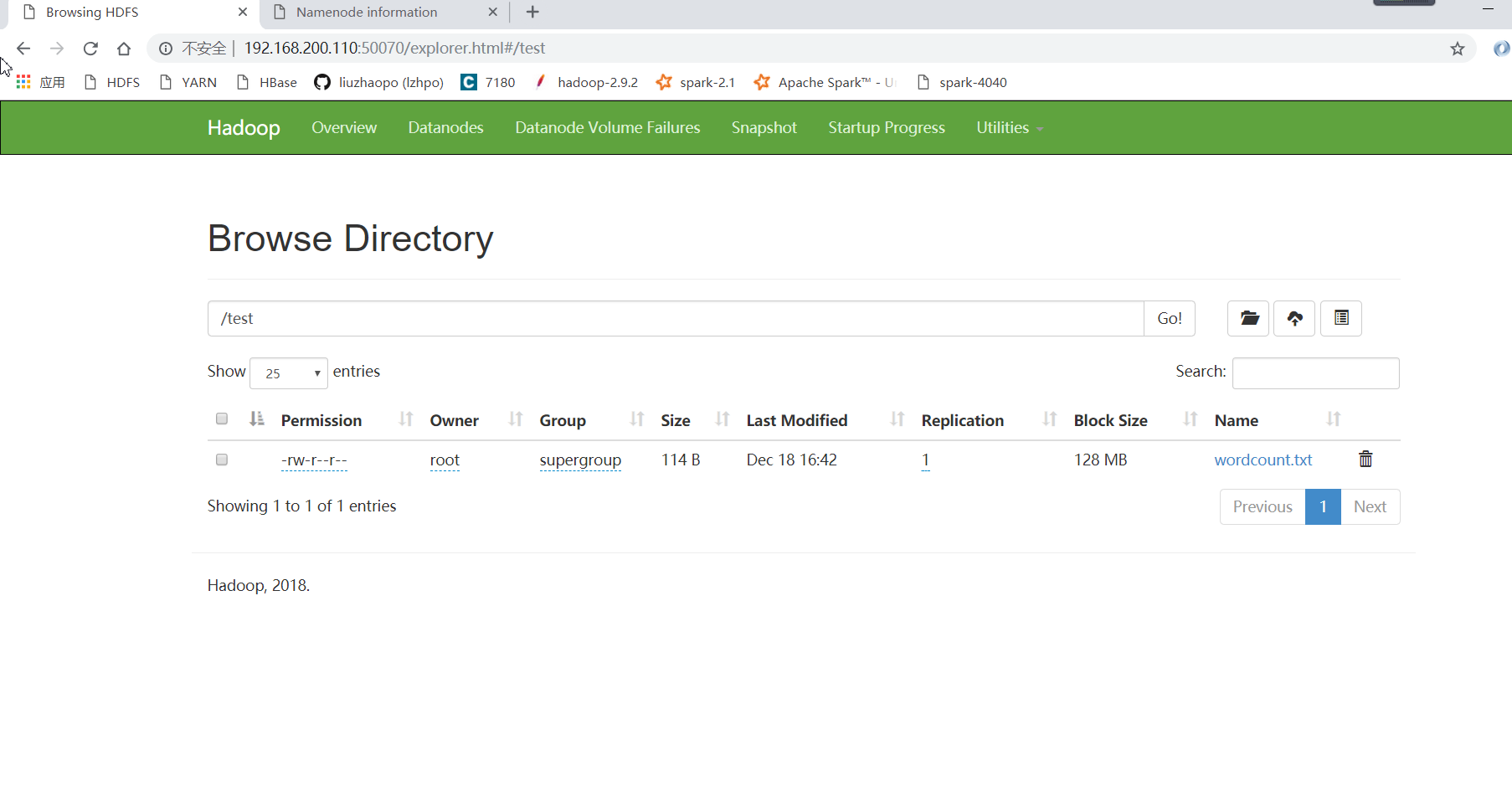
运行MapReduce的,提交job:
[root@hadoop ~]# hadoop jar /root/Hadoop/hadoop-2.9.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /test /output
注意:
*wordcount是主程序名字;/test是主程序所在的文件夹,/output是输出的结果目录。*
/root/Hadoop/hadoop-2.9.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar是hadoop自带的测试jar包。
运行过程:
[root@hadoop ~]# hadoop jar /root/Hadoop/hadoop-2.9.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /test /output
18/12/18 16:47:20 INFO client.RMProxy: Connecting to ResourceManager at /192.168.200.110:8032
18/12/18 16:47:22 INFO input.FileInputFormat: Total input files to process : 1
18/12/18 16:47:23 INFO mapreduce.JobSubmitter: number of splits:1
18/12/18 16:47:23 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/12/18 16:47:24 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545122331329_0002
18/12/18 16:47:25 INFO impl.YarnClientImpl: Submitted application application_1545122331329_0002
18/12/18 16:47:25 INFO mapreduce.Job: The url to track the job: http://hadoop:8088/proxy/application_1545122331329_0002/
18/12/18 16:47:25 INFO mapreduce.Job: Running job: job_1545122331329_0002
18/12/18 16:47:39 INFO mapreduce.Job: Job job_1545122331329_0002 running in uber mode : false
18/12/18 16:47:39 INFO mapreduce.Job: map 0% reduce 0%
18/12/18 16:47:49 INFO mapreduce.Job: map 100% reduce 0%
18/12/18 16:47:59 INFO mapreduce.Job: map 100% reduce 100%
18/12/18 16:48:00 INFO mapreduce.Job: Job job_1545122331329_0002 completed successfully
18/12/18 16:48:00 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=61
FILE: Number of bytes written=395161
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=225
HDFS: Number of bytes written=43
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7658
Total time spent by all reduces in occupied slots (ms)=5576
Total time spent by all map tasks (ms)=7658
Total time spent by all reduce tasks (ms)=5576
Total vcore-milliseconds taken by all map tasks=7658
Total vcore-milliseconds taken by all reduce tasks=5576
Total megabyte-milliseconds taken by all map tasks=7841792
Total megabyte-milliseconds taken by all reduce tasks=5709824
Map-Reduce Framework
Map input records=12
Map output records=9
Map output bytes=147
Map output materialized bytes=61
Input split bytes=111
Combine input records=9
Combine output records=3
Reduce input groups=3
Reduce shuffle bytes=61
Reduce input records=3
Reduce output records=3
Spilled Records=6
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=314
CPU time spent (ms)=2430
Physical memory (bytes) snapshot=410759168
Virtual memory (bytes) snapshot=4207472640
Total committed heap usage (bytes)=302120960
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=114
File Output Format Counters
Bytes Written=43
此时,MapReduce运行完毕之后,在HDFS上有运行结果/output/part-r-00000:
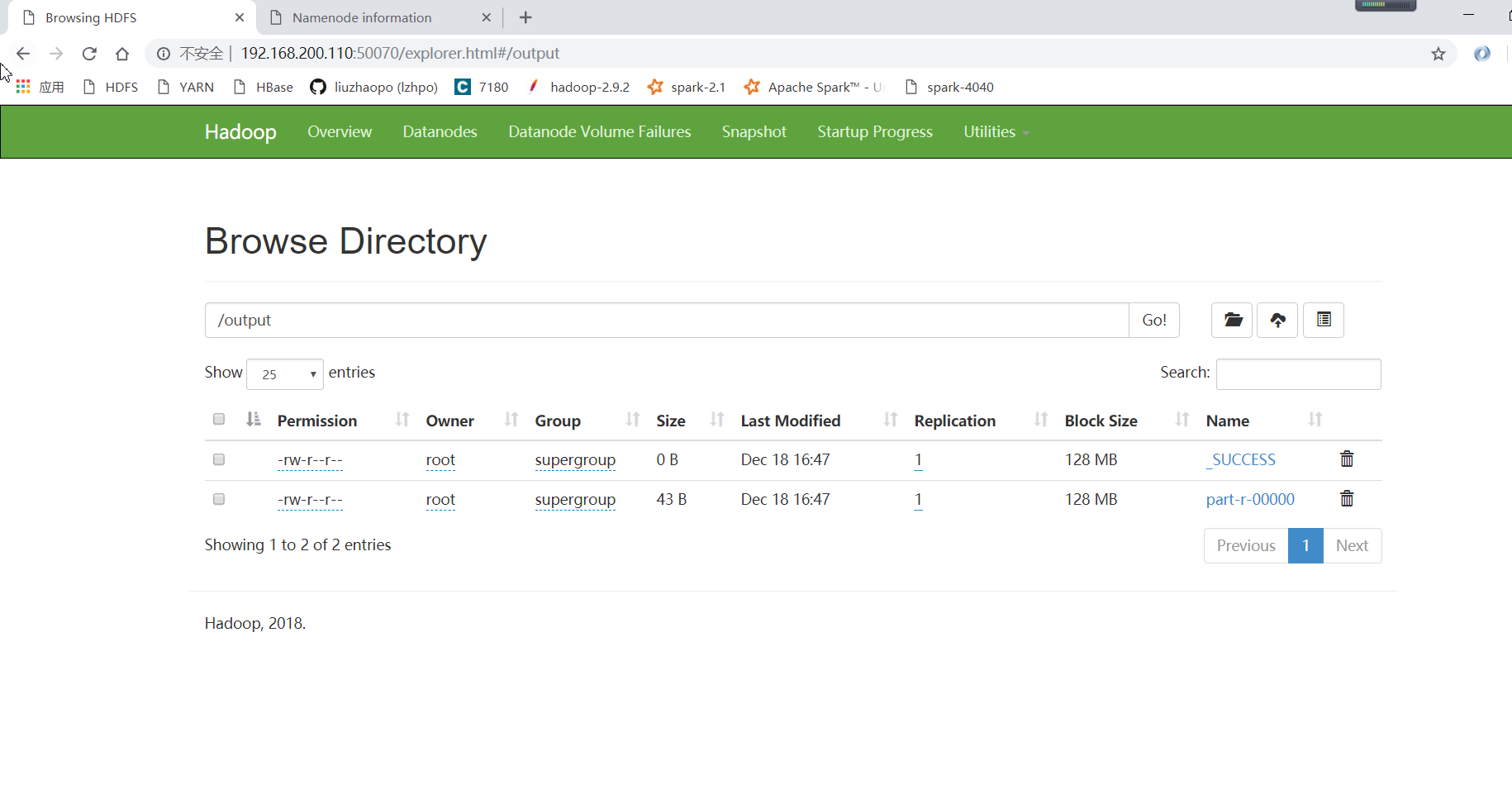
查看运行结果:
[root@hadoop ~]# hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-12-18 16:47 /output/_SUCCESS
-rw-r--r-- 1 root supergroup 43 2018-12-18 16:47 /output/part-r-00000
[root@hadoop ~]# hdfs dfs -cat /output/part-r-00000
lewis.org.cn 3
lzhpo 3
www.liuzhaopo.top 3
时间计算:大概花费了4秒钟左右的样子。
2.spark版
和hadoop版一样,创建测试文本文件:
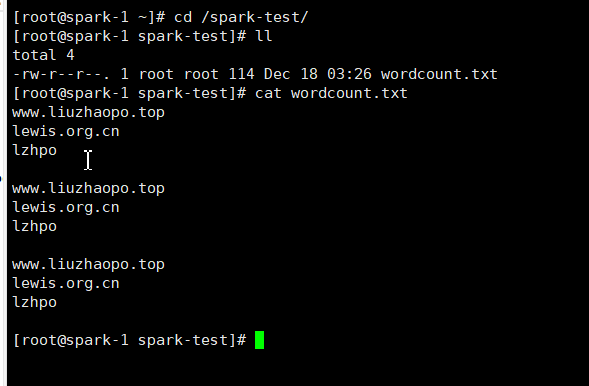
运行spark程序,一行代码即可:

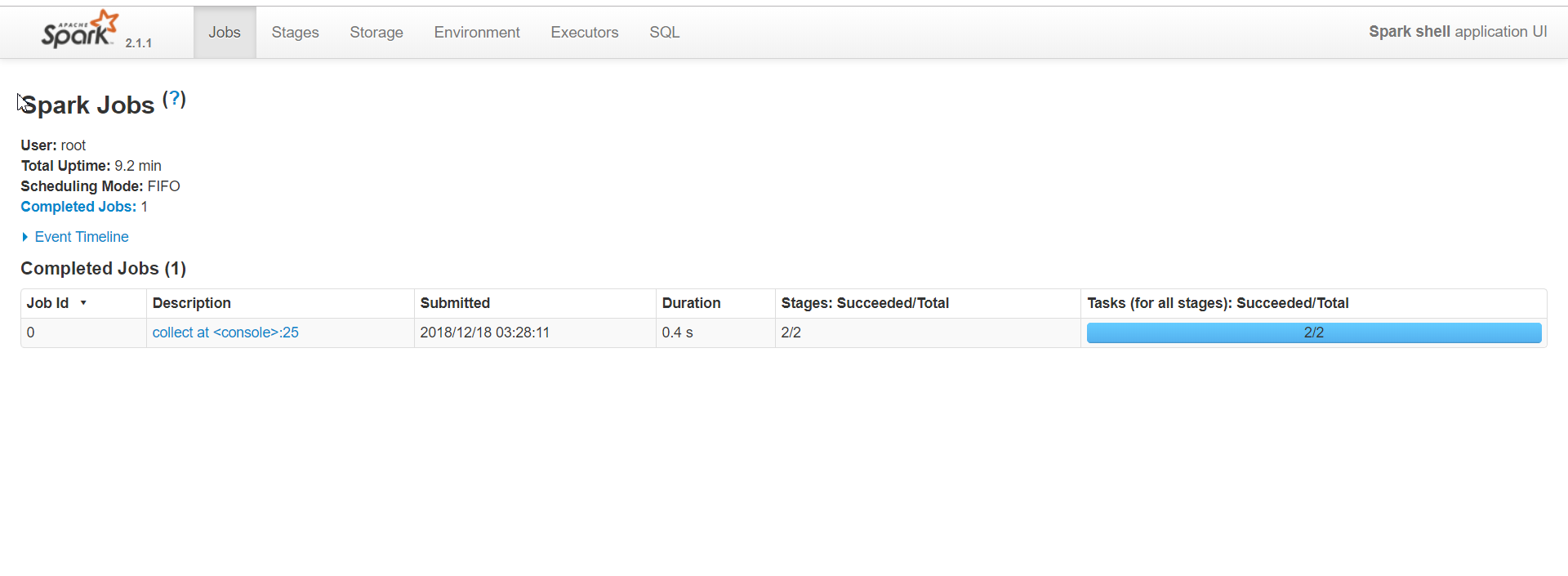
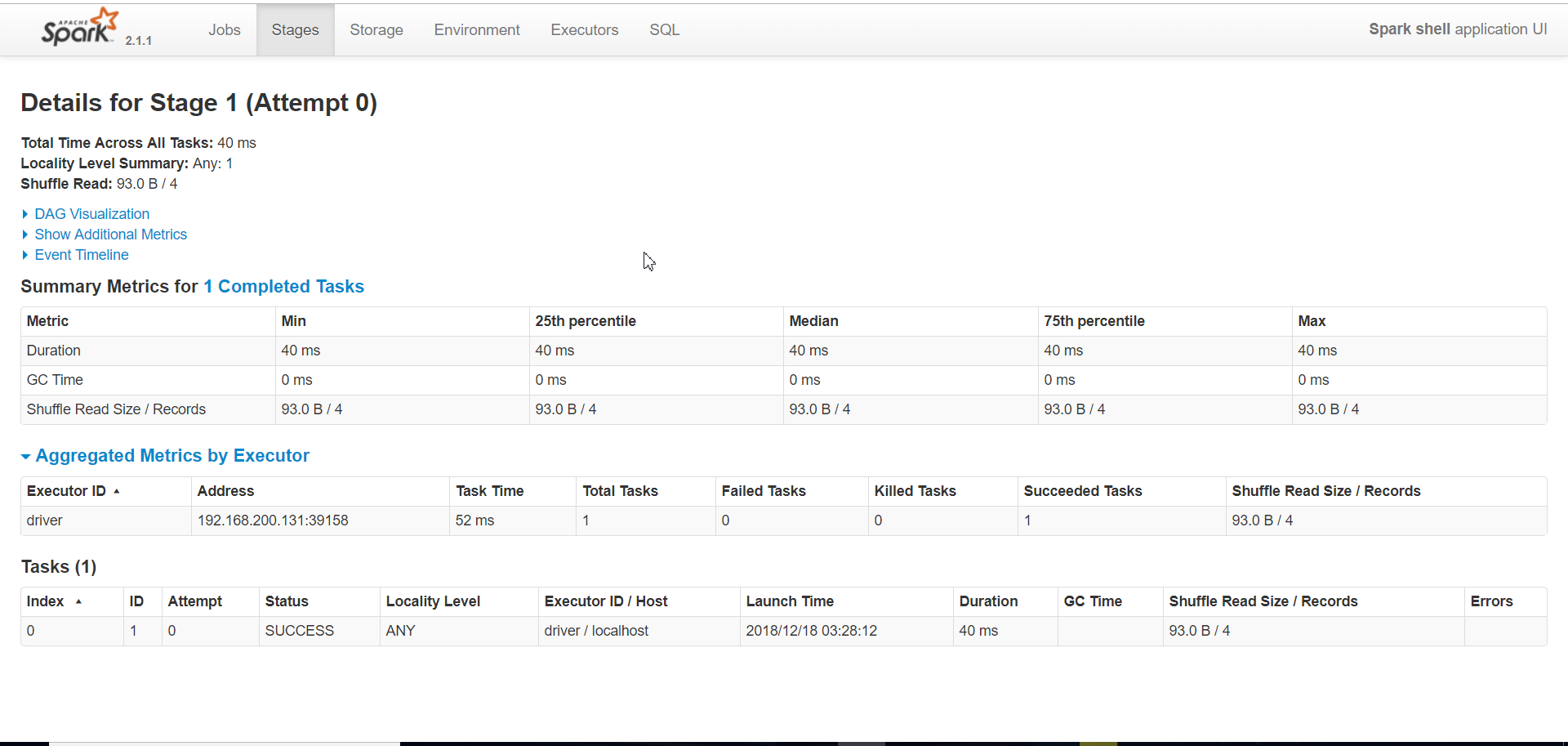
计算时间:大概一秒不到,一按确定,结果就出来了。
来web页面查看一下,果然是快如闪电:
总结
hadoop与spark,面对百万数据的时候,spark能力就发挥的淋漓尽致了,这个wordcount只是测试。
- 本文标签: Spark Hadoop
- 本文链接: http://www.lzhpo.com/article/53
- 版权声明: 本文由lzhpo原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐










相关文章
关于我

会打篮球的程序猿
Talk is cheap, show me the code.

